
Moving from rational design to ML-driven protein engineering changes how you think about selecting variants. We built Cradle around that shift, and here's what it looks like in practice.



If you've spent any time in protein engineering, you've probably done some version of this: Test a set of variants, rank them by the property you care about most, pick the top performers, and send those to seed inform the next round. Maybe you add a few wild cards based on intuition. It’s a tried-and-true discovery process, and it’s lasted this long because it works. But you’ve probably also noticed that it has a ceiling, especially when you're optimizing for more than one property at a time. Moving past that ceiling requires more than a better tool — it requires an altogether different way of thinking about how you select what to test next.
A new kind of decision-making
In rational design or directed evolution, the selection engine is your expertise. You look at structures, reason about mutations, and pick candidates based on understanding. Or you select regions to mutate, and you design clever strategies to screen hundreds or thousands of mutants that perform better than the starting sequence. Either way, your experience is a strength.
But it's also a bottleneck. Optimizing for one property, your intuition can navigate the landscape. But if you need to balance stability against activity against expression against binding affinity, the number of trade-offs grows faster than anyone can keep track of. Which 96 variants out of millions of possibilities best cover that trade-off space? It’s not a question human judgment can answer reliably. Not because you lack expertise, but because the problem is combinatorially too large.
This is where ML-driven protein engineering adds value. Not by knowing more biology than you, but by navigating a multi-dimensional space that's too complex for manual selection. Your role shifts: instead of picking individual variants, you define what success looks like — your target product profile, your constraints, your experimental capacity — and let the system figure out the best set of experiments to get there.
That's a real mindset shift, and it's worth being explicit about it. You're not giving up control. You're outsourcing the part of the job that humans are bad at (balancing dozens of trade-offs across 96 wells simultaneously) and keeping the part humans are good at (defining goals, flagging liabilities, interpreting results, setting constraints).
The problem with picking favorites
Even when people start using ML-driven tools, the instinct to pick favorites dies hard. You get a plate of 96 designed variants, and the first thing you want to do is rank them and pull out the top 10.
This makes sense if you think of each variant as an independent bet. But in a well-designed plate, variants aren't independent, they're complementary. Some are there to push boundaries on one property. Others are there to explore whether a different region of sequence space can achieve a better balance. Others are hedging against the possibility that certain predictions are wrong.
Pulling out your favorites based on a single property collapses all of that back to a narrow band.
What plate-level design actually does
Cradle designs the entire plate as a coordinated set. Think of it like the difference between one-factor-at-a-time [OFAT] experiments and proper design of experiments [DOE]. In OFAT, you optimize each variable in isolation and hope the combination works out. In DOE, you design the experiment to systematically explore how variables interact. This enables more learning per experiment because the design itself is doing work for you.
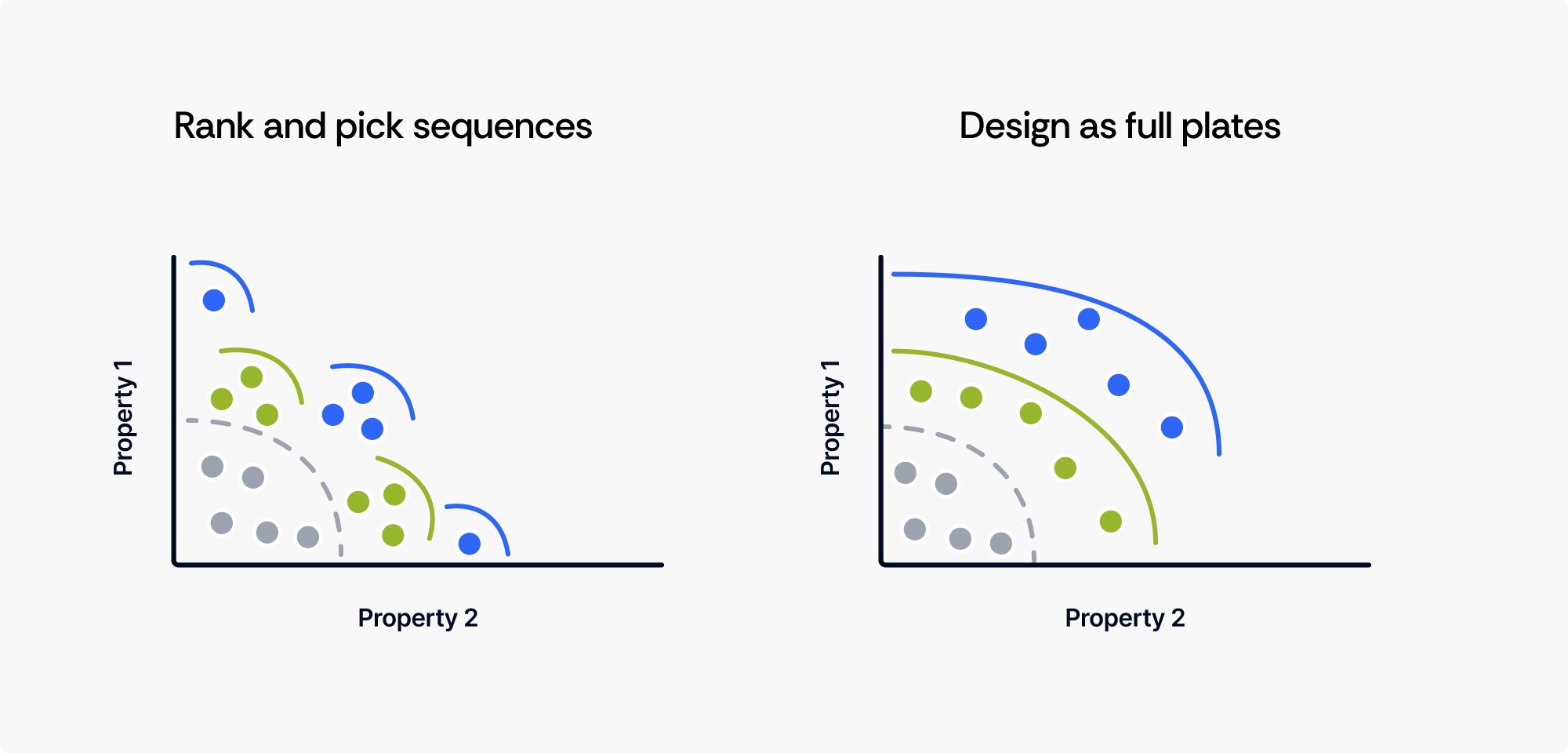
Cradle applies this logic to variant selection. Every plate is designed to:
Cover the trade-off landscape. Some variants emphasize binding affinity, others lean toward stability, others aim for balanced improvement. Together, they map out what's actually achievable so you can make informed decisions about which compromises are acceptable.
Spread risk across different assumptions. Predictions aren’t 100% accurate. If all 96 variants are betting on the same assumption, one wrong call sinks the entire round. Cradle diversifies how variants are designed so that if one bet doesn't pay off, others on the plate approaching the problem differently might well.
Maximize what you learn per round. Even variants that don't hit your target product profile generate valuable data–but only if they're spread across the landscape in a way that teaches the model something new. A plate full of near-identical variants that all succeed or fail together doesn't give you much to work with.
The result: You reach the target product profile in fewer rounds, because each plate is doing more work–both in finding winners and in understanding the shape of the landscape.
Why cherry-picking undermines this
Once you see the benefits of a plate designed as a system, it becomes clear why pulling out your "top 10" from a 96-variant design is a problem. That diverse risk coverage? Gone. The systematic exploration of trade-offs? Collapsed. The learning value of the round? Reduced.
If your experimental capacity is 48 instead of 96, the right move is to design a plate of 48 from the start. A 48-variant plate is designed with that budget in mind: the balance of risk, exploration, and optimization is calibrated to 48. It's a fundamentally different design, not a subset.
What helps Cradle do its best work
Cradle keeps the scientist in control by allowing you to set the parameters that will allow it to work best for you. A few ways you can dial the knobs to make a real difference:
Provide your actual experimental capacity. The optimization balances sequences with a high chance of success against riskier ones that might yield unexpected advantages, making different choices regarding which sequence space it explores depending on the budget. So if you can screen 96, provide that figure. If it's 48, say 48.
Don't hold back constraints. If you know certain mutations are liabilities, or you have physicochemical requirements, or you need to stay within a certain sequence space — indicate that upfront. Cradle can navigate around constraints while keeping the plate balanced. Filtering after the fact means optimizing for a problem that doesn't match your real one.
Include your controls. If you have non-negotiable sequences you want on the plate, include them in the design. Cradle will account for these when deciding what to generate for the remaining wells.
Specify your full target product profile from the start. The more properties and thresholds you define early, the more efficiently Cradle can steer toward all of them simultaneously. Adding a new constraint in round 3 that you knew about before starting round 1 means you were limiting what round 1 could achieve.
The bottom line
Protein engineering campaigns are expensive — in time, in reagents, in the opportunity cost of every round that doesn't get you closer to your goal. The shift from rational design to ML-driven workflows is a shift in where your expertise matters most: less picking individual variants, more defining what success looks like and setting the right constraints.
Cradle is built around that shift. You don't need to understand how it works under the hood. Just define your goals clearly, give it your real experimental parameters, and trust the plate. We’ll do the rest.
Recent posts
Subscribe and get new posts and updates from Cradle straight to your inbox.



